|
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简朴的聊反爬虫计谋和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相干的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相干的内容。
前面几章内容我们的爬虫程序都是单线程,在我们调试爬虫程序的时间,单线程爬虫没什么题目,但是当我们在线上情况利用单线程爬虫程序去收罗网页时,单线程就袒露出了两个致命的题目:
- 收罗效率特殊慢,单线程之间都是串行的,下一个执办法作须要等上一个执行完才能执行
- 对服务器的CUP等利用率不高,想想我们的服务器都是 8核16G,32G 的只跑一个线程会不会太浪费啦
线上情况不大概像我们本地测试一样,不在乎收罗效率,只要能精确提取结果就行。在这个时间就是款项的年代,不大概给你时间去慢慢的收罗,以是单线程爬虫程序是行不通的,我们须要将单线程改成多线程的模式,来提拔收罗效率和提高盘算机利用率。
多线程的爬虫程序计划比单线程就要复杂很多,但是与其他业务在高并发下要保证数据安全又不同,多线程爬虫在数据安全上到要求不是那么的高,由于每个页面都可以被看作是一个独立体。要做很多多少线程爬虫就必须做好两点:第一点就是同一的待收罗 URL 维护,第二点就是 URL 的去重, 下面我们简朴的来聊一聊这两点。
维护待收罗的 URL
多线程爬虫程序就不能像单线程那样,每个线程独自维护这本身的待收罗 URL,假如这样的话,那么每个线程收罗的网页将是一样的,你这就不是多线程收罗啦,你这是将一个页面收罗的多次。基于这个原因我们就须要将待收罗的 URL 同一维护,每个线程从同一 URL 维护处领取收罗 URL ,完成收罗任务,假如在页面上发现新的 URL 链接则添加到 同一 URL 维护的容器中。下面是几种得当用作同一 URL 维护的容器:
- JDK 的安全队列,比方 LinkedBlockingQueue
- 高性能的 NoSQL,好比 Redis、Mongodb
- MQ 消息中心件
URL 的去重
URL 的去重也是多线程收罗的关键一步,由于假如不去重的话,那么我们将收罗到大量重复的 URL,这样并没有提拔我们的收罗效率,好比一个分页的新闻列表,我们在收罗第一页的时间可以得到 2、3、4、5 页的链接,在收罗第二页的时间又会得到 1、3、4、5 页的链接,待收罗的 URL 队列中将存在大量的列表页链接,这样就会重复收罗乃至进入到一个死循环当中,以是就须要 URL 去重。URL 去重的方法就非常多啦,下面是几种常用的 URL 去重方式:
- 将 URL 保存到数据库举行去重,好比 redis、MongoDB
- 将 URL 放到哈希表中去重,比方 hashset
- 将 URL 颠末 MD5 之后保存到哈希表中去重,相比于上面一种,可以大概节省空间
- 利用 布隆过滤器(Bloom Filter)去重,这种方式可以大概节省大量的空间,就是不那么准确。
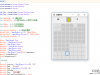
关于多线程爬虫的两个核心知识点我们都知道啦,下面我画了一个简朴的多线程爬虫架构图,如下图所示:
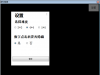
上面我们主要相识了多线程爬虫的架构计划,接下来我们不妨来试试 Java 多线程爬虫,我们以收罗虎扑新闻为例来实战一下 Java 多线程爬虫,Java 多线程爬虫中计划到了 待收罗 URL 的维护和 URL 去重,由于我们这里只是演示,以是我们就利用 JDK 内置的容器来完成,我们利用 LinkedBlockingQueue 作为待收罗 URL 维护容器,HashSet 作为 URL 去重容器。下面是 Java 多线程爬虫核心代码,详细代码以上传 GitHub,地点在文末: 我们用 5 个线程去收罗虎扑新闻列表页看看效果假如?运行该程序,得到如下结果:
结果中可以看出,我们启动了 5 个线程收罗了 61 页页面,一共耗时 2 秒钟,可以说效果照旧不错的,我们来跟单线程对比一下,看看差距有多大?我们将线程数设置为 1 ,再次启动程序,得到如下结果:
可以看出单线程收罗虎扑 61 条新闻耗费了 7 秒钟,耗时差不多是多线程的 4 倍,你想想这可只是 61 个页面,页面更多的话,差距会越来越大,以是多线程爬虫效率照旧非常高的。
分布式爬虫架构
分布式爬虫架构是一个大型收罗程序才须要利用的架构,一般情况下利用单机多线程就可以解决业务需求,反正我是没有分布式爬虫项目的履历,以是这一块我也没什么可以讲的,但是我们作为技能人员,我们须要对技能保存热度,虽然不消,但是相识相识也无妨,我查阅了不少资料得出了如下结论:
分布式爬虫架构跟我们多线程爬虫架构在思路上来说是一样的,我们只须要在多线程的底子上稍加改进就可以变成一个简朴的分布式爬虫架构。由于分布式爬虫架构中爬虫程序摆设在不同的机器上,以是我们待收罗的 URL 和 收罗过的 URL 就不能存放在爬虫程序机器的内存中啦,我们须要将它同一在某台机器上维护啦,好比存放在 Redis 大概 MongoDB 中,每台机器都从这上面获取收罗链接,而不是从 LinkedBlockingQueue 这样的内存队列中取链接啦,这样一个简朴的分布式爬虫架构就出现了,固然这内里还会有很多细节题目,由于我没有分布式架构的履历,我也无从提及,假如你有爱好的话,欢迎交换。
源代码:源代码
文章不敷之处,望各人多多指点,共同学习,共同进步
最后
打个小广告,欢迎扫码关注微信公众号:「平头哥的技能博文」,一起进步吧。
来源:https://www.cnblogs.com/jamaler/p/11683498.html | 






 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡