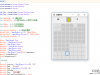
在计算机科学中,图是一种网络结构的抽象模型,它是一组由边连接的顶点组成。一个图G = (V, E)由以下元素组成:
下图表示了一个图的结构:
在介绍怎样用JavaScript实现图之前,我们先介绍一些和图相关的术语。
如上图所示,由一条边连接在一起的顶点称为相邻顶点,A和B是相邻顶点,A和D是相邻顶点,A和C是相邻顶点......A和E是不相邻顶点。一个顶点的度是其相邻顶点的数量,A和其它三个顶点相连,所以A的度为3,E和其它两个顶点相连,所以E的度为2......路径是一组相邻顶点的连续序列,如上图中包含路径ABEI、路径ACDG、路径ABE、路径ACDH等。简单路径要求路径中不包含有重复的顶点,如果将环的最后一个顶点去掉,它也是一个简单路径。例如路径ADCA是一个环,它不是一个简单路径,如果将路径中的最后一个顶点A去掉,那么它就是一个简单路径。如果图中不存在环,则称该图是无环的。如果图中任何两个顶点间都存在路径,则该图是连通的,如上图就是一个连通图。如果图的边没有方向,则该图是无向图,上图所示为无向图,反之则称为有向图,下图所示为有向图:
在有向图中,如果两个顶点间在双向上都存在路径,则称这两个顶点是强连通的,如上图中C和D是强连通的,而A和B是非强连通的。如果有向图中的任何两个顶点间在双向上都存在路径,则该有向图是强连通的,非强连通的图也称为稀疏图。
此外,图还可以是加权的。前面我们看到的图都是未加权的,下图为一个加权的图:
可以想象一下,前面我们介绍的树和链表也属于图的一种特殊形式。图在计算机科学中的应用十分广泛,例如我们可以搜索图中的一个特定顶点或一条特定的边,或者寻找两个顶点间的路径以及最短路径,检测图中是否存在环等等。
存在多种不同的方式来实现图的数据结构,下面介绍几种常用的方式。
邻接矩阵
在邻接矩阵中,我们用一个二维数组来表示图中顶点之间的连接,如果两个顶点之间存在连接,则这两个顶点对应的二维数组下标的元素的值为1,否则为0。下图是用邻接矩阵方式表示的图:
如果是加权的图,我们可以将邻接矩阵中二维数组里的值1改成对应的加权数。邻接矩阵方式存在一个缺点,如果图是非强连通的,则二维数组中会有很多的0,这表示我们使用了很多的存储空间来表示根本不存在的边。另一个缺点就是当图的顶点发生改变时,对于二维数组的修改会变得不太灵活。
邻接表
图的另外一种实现方式是邻接表,它是对邻接矩阵的一种改进。邻接表由图中每个顶点的相邻顶点列表所组成。如下图所示,我们可以用数组、链表、字典或散列表来表示邻接表。
关联矩阵
我们还可以用关联矩阵来表示图。在关联矩阵中,矩阵的行表示顶点,列表示边。关联矩阵通常用于边的数量比顶点多的情况下,以节省存储空间。如下图所示为关联矩阵方式表示的图:
下面我们重点看下怎样用邻接表的方式表示图。我们的Graph类的骨架如下,它用邻接表方式来实现无向图:- class Graph { constructor () { this.vertices = []; // 用来存放图中的顶点 this.adjList = new Dictionary(); // 用来存放图中的边 } // 向图中添加一个新顶点 addVertex (v) {} // 向图中添加a和b两个顶点之间的边 addEdge (a, b) {}}
- addVertex (v) { if (!this.vertices.includes(v)) { this.vertices.push(v); this.adjList.set(v, []); }}
- addEdge (a, b) { // 如果图中没有顶点a,先添加顶点a if (!this.adjList.has(a)) { this.addVertex(a); } // 如果图中没有顶点b,先添加顶点b if (!this.adjList.has(b)) { this.addVertex(b); } this.adjList.get(a).push(b); // 在顶点a中添加指向顶点b的边 this.adjList.get(b).push(a); // 在顶点b中添加指向顶点a的边}
下面是Graph类的完整代码,其中的toString()方法是为了我们测试用的,它的存在不是必须的。


- 1 class Graph { 2 constructor () { 3 this.vertices = []; // 用来存放图中的顶点 4 this.adjList = new Dictionary(); // 用来存放图中的边 5 } 6 7 // 向图中添加一个新顶点 8 addVertex (v) { 9 if (!this.vertices.includes(v)) {10 this.vertices.push(v);11 this.adjList.set(v, []);12 }13 }14 15 // 向图中添加a和b两个顶点之间的边16 addEdge (a, b) {17 // 如果图中没有顶点a,先添加顶点a18 if (!this.adjList.has(a)) {19 this.addVertex(a);20 }21 // 如果图中没有顶点b,先添加顶点b22 if (!this.adjList.has(b)) {23 this.addVertex(b);24 }25 26 this.adjList.get(a).push(b); // 在顶点a中添加指向顶点b的边27 this.adjList.get(b).push(a); // 在顶点b中添加指向顶点a的边28 }29 30 // 获取图的vertices31 getVertices () {32 return this.vertices;33 }34 35 // 获取图中的adjList36 getAdjList () {37 return this.adjList;38 }39 40 toString() {41 let s = '';42 this.vertices.forEach((v) => {43 s += `${v} -> `;44 this.adjList.get(v).forEach((n) => {45 s += `${n} `;46 });47 s += '\n';48 });49 return s;50 }51 }
- let graph = new Graph();let myVertices = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'];myVertices.forEach((v) => { graph.addVertex(v);});graph.addEdge('A', 'B');graph.addEdge('A', 'C');graph.addEdge('A', 'D');graph.addEdge('C', 'D');graph.addEdge('C', 'G');graph.addEdge('D', 'G');graph.addEdge('D', 'H');graph.addEdge('B', 'E');graph.addEdge('B', 'F');graph.addEdge('E', 'I');console.log(graph.toString());
- A -> B C D B -> A E F C -> A D G D -> A C G H E -> B I F -> B G -> C D H -> D I -> E
和树雷同,我们也可以对图进行遍历,以访问图中的所有顶点。图的遍历方式分为两种:广度优先(Breadth-First Search,BFS)和深度优先(Depth-First Search,DFS)。对图的遍历可以用来寻找特定的顶点或两个顶点之间的最短路径,以及检查图是否连通、图中是否含有环等。
| 算法 | 数据结构 | 描述 | | 深度优先 | 栈 | 将图的顶点存入栈中(有关栈的介绍可以参考《JavaScript数据结构——栈的实现与应用》),顶点是沿着路径被探索的,存在新的相邻顶点就去访问。 | | 广度优先 | 队列 | 将图的顶点存入队列中(有关队列的介绍可以参考《JavaScript数据结构——队列的实现与应用》),最先入队列的顶点先被探索。 |
在接下来要实现的算法中,我们按照如下的约定对图中的顶点进行遍历,每个顶点最多访问两次:
- 白色:表示该顶点未被访问。
- 灰色:表示该顶点被访问过,但未被探索。
- 黑色:表示该顶点被访问并且被探索过。
广度优先
广度优先算法会从指定的第一个顶点开始遍历图,先访问这个顶点的所有相邻顶点,然后再访问这些相邻顶点的相邻顶点,以此类推。最终,广度优先算法会先广后深地访问图中的所有顶点。下面是广度优先遍历的示意图:
由于我们采用邻接表的方式来存储图的数据,对于图的每个顶点,都有一个字典与之对应,字典的键值为顶点的值,字典的内容为与该顶点相邻的顶点列表。基于这种数据结构,我们可以考虑将所有顶点的邻接顶点存入队列,然后依次处理队列中的顶点。下面是具体的遍历步骤:
- 将开始顶点存入队列。
- 遍历开始顶点的所有邻接顶点,如果这些邻接顶点没有被访问过(颜色为白色),则将它们标记为被访问(颜色为灰色),然后加入队列。
- 将开始顶点标记为被处理(颜色为黑色)。
- 循环处理队列中的顶点,直到队列为空。
下面是该算法的具体实现:- let Colors = { WHITE: 0, GREY: 1, BLACK: 2};let initializeColor = vertices => { let color = {}; vertices.forEach(v => color[v] = Colors.WHITE); return color;};let breadthFirstSearch = (graph, startVertex, callback) => { let vertices = graph.getVertices(); let adjList = graph.getAdjList(); let color = initializeColor(vertices); let queue = new Queue(); queue.enqueue(startVertex); while (!queue.isEmpty()) { let u = queue.dequeue(); adjList.get(u).forEach(n => { if (color[n] === Colors.WHITE) { color[n] = Colors.GREY; queue.enqueue(n); } }); color[u] = Colors.BLACK; if (callback) callback(u); }};
首先通过initializeColor()函数将所有的顶点标记为未被访问过(颜色为白色),这些颜色保存在以顶点值为key的color对象中。图的vertices和adjList属性可以通过getVertices()和getAdjList()方法得到,然后构造一个队列queue(有关队列类Queue请参考《JavaScript数据结构——队列的实现与应用》),按照上面描述的步骤对图的顶点进行遍历。
在前面我们给出的测试用例的基础上,添加下面的代码,来看看breadthFirstSearch()方法的执行结果:- breadthFirstSearch(graph, 'A', value => console.log(`visited vertex: ${value}`));
- visited vertex: Avisited vertex: Bvisited vertex: Cvisited vertex: Dvisited vertex: Evisited vertex: Fvisited vertex: Gvisited vertex: Hvisited vertex: I
- visited vertex: Ivisited vertex: Evisited vertex: Bvisited vertex: Avisited vertex: Fvisited vertex: Cvisited vertex: Dvisited vertex: Gvisited vertex: H
寻找最短路径
前面展示了广度优先算法的工作原理,我们可以使用它做更多的事情,例如在一个图G中,从顶点v开始到其它所有顶点间的最短距离。我们考虑一下怎样用BFS来实现寻找最短路径。
假设两个相邻顶点间的距离为1,从顶点v开始,在其路径上每颠末一个顶点,距离加1。下面是对breadthFirstSearch()方法的改进,用来返回从起始顶点开始到其它所有顶点间的距离,以及所有顶点的前置顶点。- let BFS = (graph, startVertex) => { let vertices = graph.getVertices(); let adjList = graph.getAdjList(); let color = initializeColor(vertices); let queue = new Queue(); let distances = {}; let predecessors = {}; queue.enqueue(startVertex); // 初始化所有顶点的距离为0,前置节点为null vertices.forEach(v => { distances[v] = 0; predecessors[v] = null; }); while (!queue.isEmpty()) { let u = queue.dequeue(); adjList.get(u).forEach(n => { if (color[n] === Colors.WHITE) { color[n] = Colors.GREY; distances[n] = distances[u] + 1; predecessors[n] = u; queue.enqueue(n); } }); color[u] = Colors.BLACK; } return {distances, predecessors};};
- console.log(BFS(graph, 'A'));
- { distances: { A: 0, B: 1, C: 1, D: 1, E: 2, F: 2, G: 2, H: 2, I: 3 }, predecessors: { A: null, B: 'A', C: 'A', D: 'A', E: 'B', F: 'B', G: 'C', H: 'D', I: 'E' }}
- let shortestPathA = BFS(graph, 'A');let startVertex = 'A';myVertices.forEach(v => { let path = new Stack(); for (let v2 = v; v2 !== startVertex; v2 = shortestPathA.predecessors[v2]) { path.push(v2); } path.push(startVertex); let s = path.pop(); while (!path.isEmpty()) { s += ` - ${path.pop()}`; } console.log(s);});
- AA - BA - CA - DA - B - EA - B - FA - C - GA - D - HA - B - E - I
Dijkstra - 寻找从指定顶点到其它所有顶点的最短路径的贪心算法。
- 1 const INF = Number.MAX_SAFE_INTEGER; 2 const minDistance = (dist, visited) => { 3 let min = INF; 4 let minIndex = -1; 5 for (let v = 0; v < dist.length; v++) { 6 if (visited[v] === false && dist[v] {14 const dist = [];15 const visited = [];16 const { length } = graph;17 for (let i = 0; i < length; i++) {18 dist[i] = INF;19 visited[i] = false;20 }21 dist[src] = 0;22 for (let i = 0; i < length - 1; i++) {23 const u = minDistance(dist, visited);24 visited[u] = true;25 for (let v = 0; v < length; v++) {26 if (!visited[v] && graph[u][v] !== 0 && dist[u] !== INF && dist[u] + graph[u][v] < dist[v]) {27 dist[v] = dist[u] + graph[u][v];28 }29 }30 }31 return dist;32 };
- 1 const floydWarshall = graph => { 2 const dist = []; 3 const { length } = graph; 4 for (let i = 0; i < length; i++) { 5 dist[i] = []; 6 for (let j = 0; j < length; j++) { 7 if (i === j) { 8 dist[i][j] = 0; 9 } else if (!isFinite(graph[i][j])) {10 dist[i][j] = Infinity;11 } else {12 dist[i][j] = graph[i][j];13 }14 }15 }16 for (let k = 0; k < length; k++) {17 for (let i = 0; i < length; i++) {18 for (let j = 0; j < length; j++) {19 if (dist[i][k] + dist[k][j] < dist[i][j]) {20 dist[i][j] = dist[i][k] + dist[k][j];21 }22 }23 }24 }25 return dist;26 };


- 1 const INF = Number.MAX_SAFE_INTEGER; 2 const find = (i, parent) => { 3 while (parent[i]) { 4 i = parent[i]; // eslint-disable-line prefer-destructuring 5 } 6 return i; 7 }; 8 const union = (i, j, parent) => { 9 if (i !== j) {10 parent[j] = i;11 return true;12 }13 return false;14 };15 const initializeCost = graph => {16 const cost = [];17 const { length } = graph;18 for (let i = 0; i < length; i++) {19 cost[i] = [];20 for (let j = 0; j < length; j++) {21 if (graph[i][j] === 0) {22 cost[i][j] = INF;23 } else {24 cost[i][j] = graph[i][j];25 }26 }27 }28 return cost;29 };30 const kruskal = graph => {31 const { length } = graph;32 const parent = [];33 let ne = 0;34 let a;35 let b;36 let u;37 let v;38 const cost = initializeCost(graph);39 while (ne < length - 1) {40 for (let i = 0, min = INF; i < length; i++) {41 for (let j = 0; j < length; j++) {42 if (cost[i][j] < min) {43 min = cost[i][j];44 a = u = i;45 b = v = j;46 }47 }48 }49 u = find(u, parent);50 v = find(v, parent);51 if (union(u, v, parent)) {52 ne++;53 }54 cost[a][b] = cost[b][a] = INF;55 }56 return parent;57 };
- 1 const INF = Number.MAX_SAFE_INTEGER; 2 const minKey = (graph, key, visited) => { 3 // Initialize min value 4 let min = INF; 5 let minIndex = 0; 6 for (let v = 0; v < graph.length; v++) { 7 if (visited[v] === false && key[v] < min) { 8 min = key[v]; 9 minIndex = v;10 }11 }12 return minIndex;13 };14 const prim = graph => {15 const parent = [];16 const key = [];17 const visited = [];18 const { length } = graph;19 for (let i = 0; i < length; i++) {20 key[i] = INF;21 visited[i] = false;22 }23 key[0] = 0;24 parent[0] = -1;25 for (let i = 0; i < length - 1; i++) {26 const u = minKey(graph, key, visited);27 visited[u] = true;28 for (let v = 0; v < length; v++) {29 if (graph[u][v] && !visited[v] && graph[u][v] < key[v]) {30 parent[v] = u;31 key[v] = graph[u][v];32 }33 }34 }35 return parent;36 };
深度优先算法从图的第一个顶点开始,沿着这个顶点的一条路径递归查找到最后一个顶点,然后返回并探查路径上的其它路径,直到所有路径都被访问到。最终,深度优先算法会先深后广地访问图中的所有顶点。下面是深度优先遍历的示意图:
我们仍然采用和广度优先算法一样的思路,一开始将所有的顶点初始化为白色,然后沿着路径递归探查其余顶点,当顶点被访问过,将颜色改为灰色,如果顶点被探索过(处理过),则将颜色改为黑色。下面是深度优先算法的具体实现:- let depthFirstSearchVisit = (u, color, adjList, callback) => { color[u] = Colors.GREY; if (callback) callback(u); adjList.get(u).forEach(n => { if (color[n] === Colors.WHITE) { depthFirstSearchVisit(n, color, adjList, callback); } }); color[u] = Colors.BLACK;};let depthFirstSearch = (graph, callback) => { let vertices = graph.getVertices(); let adjList = graph.getAdjList(); let color = initializeColor(vertices); vertices.forEach(v => { if (color[v] === Colors.WHITE) { depthFirstSearchVisit(v, color, adjList, callback); } });};
- 将图中所有顶点的颜色初始化为白色。
- 遍历顶点,此时A作为第一个顶点,它的颜色为白色,于是调用函数depthFirstSearchVisit(),并将顶点A、color、graph.adjList作为参数传入。
- 在depthFirstSearchVisit()函数内部,由于顶点A被访问过了,所以将颜色设置为灰色,并执行callback回调函数(如果存在),然后遍历A的邻接顶点B、C、D。
- B未被访问过,颜色为白色,所以将B作为参数递归调用depthFirstSearchVisit()函数。B设置为灰色,callback('B')。遍历B的邻接节点E和F。
- E未被访问过,颜色为白色,所以将E作为参数递归调用depthFirstSearchVisit()函数。E设置为灰色,callback('E')。遍历E的邻接节点I。
- I未被访问过,颜色为白色,所以将I作为参数递归调用depthFirstSearchVisit()函数。I设置为灰色,callback('I')。I没有邻接节点,然后将I设置为黑色。递归返回到5。
- E没有其它邻接节点,将E设置为黑色。递归返回到4。
- 遍历B的另一个邻接节点F,F未被访问过,颜色为白色,所以将F作为参数递归调用depthFirstSearchVisit()函数。F设置为灰色,callback('F')。F没有邻接节点,然后将F设置为黑色。递归返回到4。
- B的所有邻接节点都被访问过了,将B设置为黑色。递归返回到3。
- 访问A的第二个邻接节点C,C未被访问过,颜色为白色,所以将C作为参数递归调用depthFirstSearchVisit()函数。C设置为灰色,callback('C')。遍历C的邻接节点D、G。
- D未被访问过,颜色为白色,所以将D作为参数递归调用depthFirstSearchVisit()函数。D设置为灰色,callback('D')。遍历D的邻接节点G和H。
- G未被访问过,颜色为白色,所以将G作为参数递归调用depthFirstSearchVisit()函数。G设置为灰色,callback('G')。G没有邻接节点,然后将G设置为黑色。递归返回到11。
- 遍历D的另一个邻接节点H,H未被访问过,颜色为白色,所以将H作为参数递归调用depthFirstSearchVisit()函数。H设置为灰色,callback('H')。H没有邻接节点,然后将H设置为黑色。递归返回到11。
- D的所有邻接节点都被访问过了,将D设置为黑色。递归返回到10。
- 遍历C的另一个邻接节点G,由于G已经被访问过,对C的邻接节点的遍历竣事。将C设置为黑色。递归返回到3。
- 访问A的最后一个邻接节点D,由于D已经被访问过,对A的邻接节点的遍历竣事。将A设置为黑色。
- 然后对剩余的节点进行遍历。由于剩余的节点都被设置为黑色了,所以程序竣事。
对应的测试用例及执行结果如下:- depthFirstSearch(graph, value => console.log(`visited vertex: ${value}`));
- visited vertex: Avisited vertex: Bvisited vertex: Evisited vertex: Ivisited vertex: Fvisited vertex: Cvisited vertex: Dvisited vertex: Gvisited vertex: H
前面说过,深度优先算法的数据结构是栈,然而这里我们并没有使用栈来存储任何数据,而是使用了函数的递归调用,其实递归也是栈的一种表现形式。另外一点,如果图是连通的(即图中任何两个顶点之间都存在路径),我们可以对上述代码中的depthFirstSearch()方法进行改进,只需要对图的起始顶点开始遍历一次就可以了,而不需要遍历图的所有顶点,因为从起始顶点开始的递归就可以覆盖图的所有顶点。
拓扑排序
前面展示了深度优先算法的工作原理,我们可以使用它做更多的事情,例如拓扑排序(toplogical sorting,也叫做topsort或者toposort)。与广度优先算法雷同,我们也对上面的depthFirstSeach()方法进行改进,以说明怎样使用深度优先算法来实现拓扑排序:- let DFSVisit = (u, color, discovery, finished, predecessors, time, adjList) => { color[u] = Colors.GREY; discovery[u] = ++time.count; adjList.get(u).forEach(n => { if (color[n] === Colors.WHITE) { predecessors[n] = u; DFSVisit(n, color, discovery, finished, predecessors, time, adjList); } }); color[u] = Colors.BLACK; finished[u] = ++time.count;};let DFS = graph => { let vertices = graph.getVertices(); let adjList = graph.getAdjList(); let color = initializeColor(vertices); let discovery = {}; let finished = {}; let predecessors = {}; let time = { count: 0 }; vertices.forEach(v => { finished[v] = 0; discovery[v] = 0; predecessors[v] = null; }); vertices.forEach(v => { if (color[v] === Colors.WHITE) { DFSVisit(v, color, discovery, finished, predecessors, time, adjList); } }); return {discovery, finished, predecessors};};
来看看对DFS()方法的测试结果:- { discovery: { A: 1, B: 2, C: 10, D: 11, E: 3, F: 7, G: 12, H: 14, I: 4 }, finished: { A: 18, B: 9, C: 17, D: 16, E: 6, F: 8, G: 13, H: 15, I: 5 }, predecessors: { A: null, B: 'A', C: 'A', D: 'C', E: 'B', F: 'B', G: 'D', H: 'D', I: 'E' }}
示意图上每一个顶点左边的数字是顶点的发现时间,右边的数字是顶点的探索时间,全部完成时间是18,可以联合前面的深度优先算法遍历过程示意图来看,它们是对应的。同时我们也看到,深度优先算法的predecessors和广度优先算法的predecessors会有所不同。
拓扑排序只能应用于有向无环图(DAG)。基于上面DFS()方法的返回结果,我们可以对顶点的完成时间(探索时间finished)进行排序,以得到我们需要的拓扑排序结果。
如果要实现有向图,只需要对前面我们实现的Graph类的addEdge()方法略加修改,将最后一行删掉。当然,我们也可以在Graph类的构造函数中指明是有向图还是无向图,下面是改进后的Graph类:
- 1 class Graph { 2 constructor (isDirected = false) { 3 this.isDirected = isDirected; 4 this.vertices = []; // 用来存放图中的顶点 5 this.adjList = new Dictionary(); // 用来存放图中的边 6 } 7 8 // 向图中添加一个新顶点 9 addVertex (v) {10 if (!this.vertices.includes(v)) {11 this.vertices.push(v);12 this.adjList.set(v, []);13 }14 }15 16 // 向图中添加a和b两个顶点之间的边17 addEdge (a, b) {18 // 如果图中没有顶点a,先添加顶点a19 if (!this.adjList.has(a)) {20 this.addVertex(a);21 }22 // 如果图中没有顶点b,先添加顶点b23 if (!this.adjList.has(b)) {24 this.addVertex(b);25 }26 27 this.adjList.get(a).push(b); // 在顶点a中添加指向顶点b的边28 if (this.isDirected !== true) {29 this.adjList.get(b).push(a); // 如果为无向图,则在顶点b中添加指向顶点a的边30 }31 }32 33 // 获取图的vertices34 getVertices () {35 return this.vertices;36 }37 38 // 获取图中的adjList39 getAdjList () {40 return this.adjList;41 }42 43 toString() {44 let s = '';45 this.vertices.forEach((v) => {46 s += `${v} -> `;47 this.adjList.get(v).forEach((n) => {48 s += `${n} `;49 });50 s += '\n';51 });52 return s;53 }54 }
- let graph = new Graph();let myVertices = ['A', 'B', 'C', 'D', 'E', 'F'];myVertices.forEach((v) => { graph.addVertex(v);});graph.addEdge('A', 'C');graph.addEdge('A', 'D');graph.addEdge('B', 'D');graph.addEdge('B', 'E');graph.addEdge('C', 'F');graph.addEdge('F', 'E');console.log(DFS(graph));
- { discovery: { A: 1, B: 11, C: 2, D: 8, E: 4, F: 3 }, finished: { A: 10, B: 12, C: 7, D: 9, E: 5, F: 6 }, predecessors: { A: null, B: null, C: 'A', D: 'A', E: 'F', F: 'C' }}
对顶点的完成时间进行倒序排序,得到的拓扑排序结果为:B - A - D - C - F - E。
下一章我们将介绍怎样用JavaScript来实现各种常见的排序算法。
来源:https://www.cnblogs.com/jaxu/archive/2019/08/14/11338294.html |























 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡