马上加入IBC程序猿 各种源码随意下,各种教程随便看! 注册 每日签到 加入编程讨论群
C#教程 ASP.NET教程 C#视频教程程序源码享受不尽 C#技术求助 ASP.NET技术求助
【源码下载】 社群合作 申请版主 程序开发 【远程协助】 每天乐一乐 每日签到 【承接外包项目】 面试-葵花宝典下载
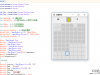
首先咱们说哈,爬虫不是“虫子”,姑凉们不要害怕。
模拟客户端发送网络请求,可设置请求参数、header头信息
类jQuery库,可将字符串导入,创建对象,用于快速抓取字符串中的符合条件的数据
友情提醒:每个网站的HTML结构是不一样,在抓取不同网站的数据时,要分析不同的解构,才能百发百中。
获取到信息之后,做接口数据返回、存储数据库,你想干啥都行...
胡哥有话说,一个有技术,有情怀的胡哥!京东开放平台首席前端攻城狮。与你一起聊聊大前端,分享前端系统架构,框架实现原理,最新最高效的技术实践!
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
积极宣传本站,为本站带来更多注册会员
长期对论坛的繁荣而不断努力,或多次提出建设性意见
活跃且尽责职守的版主
曾经为论坛做出突出贡献目前已离职的版主
为论坛做出突出贡献的会员







 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡